
In today’s blog post, we’re going to explore the world of hash tables and how they can be implemented in C++. We’ll start with the basics, understanding what a hash table is and we’ll keep things simple and easy to follow.
We’ll also touch on some key topics, such as the differences between hash tables and linked lists, the fundamental principles behind hash tables, and of course, the practical aspects of implementing them in C++.
What is hash table?
Let’s start by unraveling the mystery of a hash table. Imagine a giant, digital filing cabinet where you want to store various items. Now, this cabinet is so enormous that finding things manually would take forever. Here’s where a hash table comes in handy. Think of it as a smart organizer. Instead of randomly throwing items into the cabinet, each item gets a unique tag, much like a label on a file folder. This tag, known as a “hash value,” is generated by a special function. When you want to find a specific item later, you don’t need to search through the entire cabinet. You use the tag, and voila! The hash table swiftly directs you to the right spot. In simpler terms, a hash table is like a magical index that helps computers find information quickly and efficiently. It’s this clever organization that makes hash tables one of the most fundamental tools in computer science, ensuring speedy access to data in various applications.
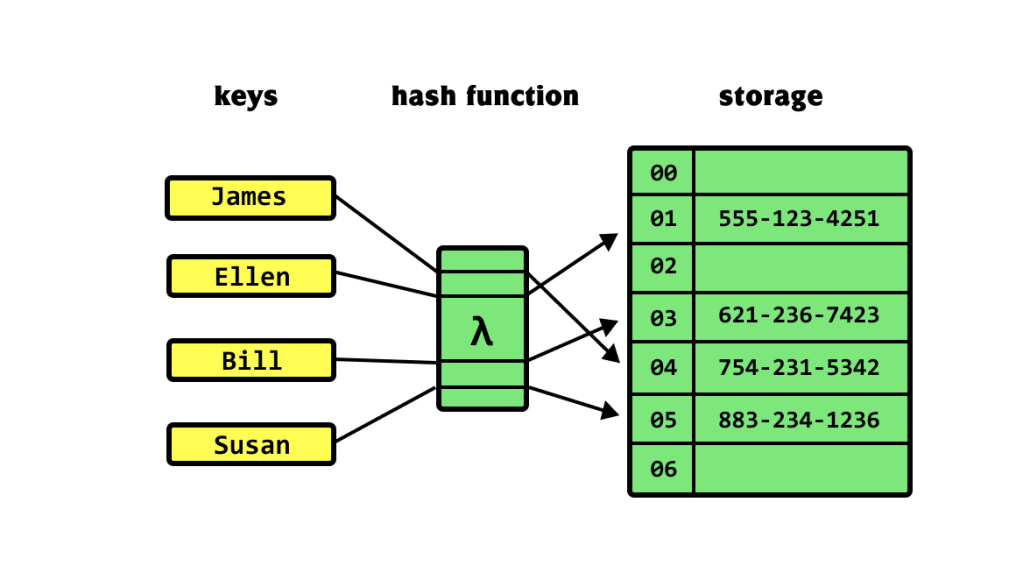
One of the remarkable features of a hash table is its constant access speed. Regardless of how much data you store, the time it takes to find, insert, or delete an item remains nearly the same. This consistency is possible because of the unique hash value assigned to each item. When you need to access an element, the hash table instantly calculates its location based on this value. Whether you have ten items or a million, the hash table’s algorithm ensures that retrieving information is lightning-fast. This constant time complexity, often referred to as O(1), makes hash tables incredibly efficient for tasks requiring speedy data access and retrieval.
Linked list vs hash table
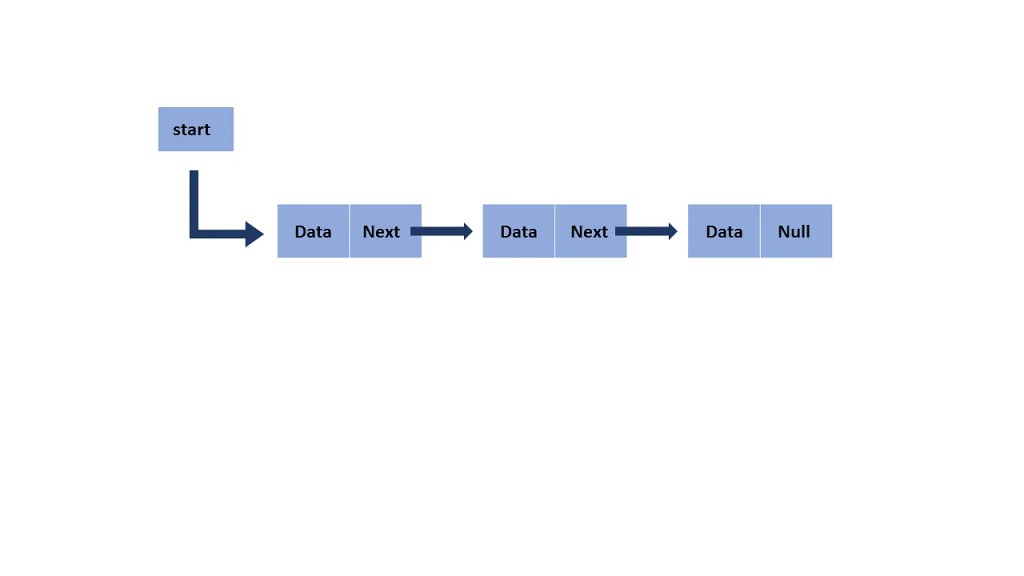
When it comes to organizing data, both linked lists and hash tables have their unique strengths. Linked lists are like a series of connected dots, where each element points to the next one in line. They’re excellent for maintaining an ordered sequence of items, allowing for easy insertion and deletion of elements. However, finding a specific item in a linked list can be time-consuming, especially if the list is long, because you need to traverse through each element until you find the desired one. On the other hand, hash tables use a clever hashing mechanism to provide rapid data access. Instead of being linear like a linked list, a hash table provides constant-time access to stored elements. This speed comes from the use of hash functions, ensuring that each item is mapped to a unique location within the table. So, while linked lists excel in maintaining order, hash tables shine in terms of quick and efficient data retrieval, making them a popular choice in various computer science applications.
Hash table implementation on C++
I’ll start by showcasing the complete code, providing you with an overview of the entire implementation in one glance. Following that, we will delve into the intricacies of the hash function. Beginning with a comprehensive view of the code allows you to understand the overall structure before we focus on the specifics. By adopting this approach, we can ensure a clear understanding of the implementation as a whole, making it easier to grasp the role and importance of the hash function in our hash table. Let’s explore the code together, and then we’ll shine a spotlight on the essential details of the hash function.
#include <string>
#include <vector>
#include <array>
#include <functional>
struct person {
std::string name;
int age{0};
};
class hashTable
{
public:
hashTable(){}
~hashTable() {}
bool insertPerson(person p)
{
// check if table is full
if (m_numberPeople >= m_tableSize)
return false;
// hasher object for string
std::hash<std::string> hasher;
// hash value which represents index of person in array
int hashValue = hasher(p.name) % m_tableSize;
// check if same name already exist
if (!m_people[hashValue].name.empty())
return false;
m_people[hashValue] = p;
++m_numberPeople;
return true;
}
bool deletePerson(std::string name)
{
// hasher object for string
std::hash<std::string> hasher;
// hash value which represents index of person in array
int hashValue = hasher(name) % m_tableSize;
// person doesnt exist
if (m_people[hashValue].name.empty())
return false;
m_people[hashValue].name.clear();
m_people[hashValue].age = 0;
–m_numberPeople;
return true;
}
int getAge(std::string name)
{
std::hash<std::string> hasher; // std::hash object for strings
int hashValue = hasher(name) % m_tableSize;
if (m_people[hashValue].name.empty())
return -1;
return m_people[hashValue].age;
}
void printAll()
{
std::cout << “Start” << std::endl;
for (auto& person : m_people)
{
std::cout << “\tName : ” << person.name << std::endl;
}
std::cout << “End” << std::endl;
}
private:
static constexpr int m_tableSize{ 20 };
std::array<person, m_tableSize> m_people;
int m_numberPeople{0};
};
int main()
{
person ahmet{ “mert”, 15 };
person mehmet{ “mehmet”, 20 };
person ayse{ “ayse”, 25 };
person ali{ “ali”, 30 };
hashTable myTable;
myTable.insertPerson(ahmet);
myTable.insertPerson(mehmet);
myTable.insertPerson(ayse);
myTable.insertPerson(ali);
myTable.printAll();
myTable.deletePerson(“ali”);
myTable.printAll();
std::cout << “ozgur Age : ” << myTable.getAge(“ozgur”) << std::endl;
std::cout << “mert Age : ” << myTable.getAge(“mert”) << std::endl;
std::cout << “mehmet Age : ” << myTable.getAge(“mehmet”) << std::endl;
std::cout << “sena Age : ” << myTable.getAge(“sena”) << std::endl;
std::cout << “ayse Age : ” << myTable.getAge(“ayse”) << std::endl;
std::cout << “ali Age : ” << myTable.getAge(“ali”) << std::endl;
return 0;
}
Hash function
The first crucial point to underline is the hash function. This function plays a fundamental role by generating a unique key, often referred to as a hash value, for each item within the hash table. This hash value serves as an address, allowing us to locate the corresponding item efficiently. However, creating an effective hash function involves meeting specific requirements. It must produce unique hash values for different inputs, ensuring distinct items don’t share the same location within the table. Additionally, the hash function should be deterministic, meaning it consistently generates the same hash value for the same input. By fulfilling these requirements, the hash function becomes the cornerstone of our hash table, enabling precise and swift data retrieval. As we delve deeper, we’ll explore these requirements in detail, shedding light on their significance in creating a reliable hash table implementation.
While you have the flexibility to create a custom hash function tailored to your specific needs, in our implementation, we opted for simplicity and efficiency by utilizing the std::hash function from the C++ standard library. This built-in function is designed to generate hash values for a wide range of data types. By leveraging the std::hash template function, we ensure a reliable and standardized approach to hashing, simplifying the implementation process and allowing us to focus on other aspects of the hash table logic. This choice underscores the convenience of utilizing established libraries in C++, streamlining the development process and enabling us to create a functional hash table with confidence.
Please note that this example is not the most efficient way to implement a hash table. Its purpose is to serve as an illustrative demonstration of hash table implementation concepts rather than being the pinnacle of efficiency. Throughout our exploration, our primary goal is to provide a clear understanding of the fundamental principles behind hash tables in C++. While the implementation might not be the most optimized version, it will lay a solid foundation for grasping key concepts. Let’s proceed with this understanding, keeping in mind that our focus is on comprehension rather than optimization.
Also, you can check std::unordered_map.
